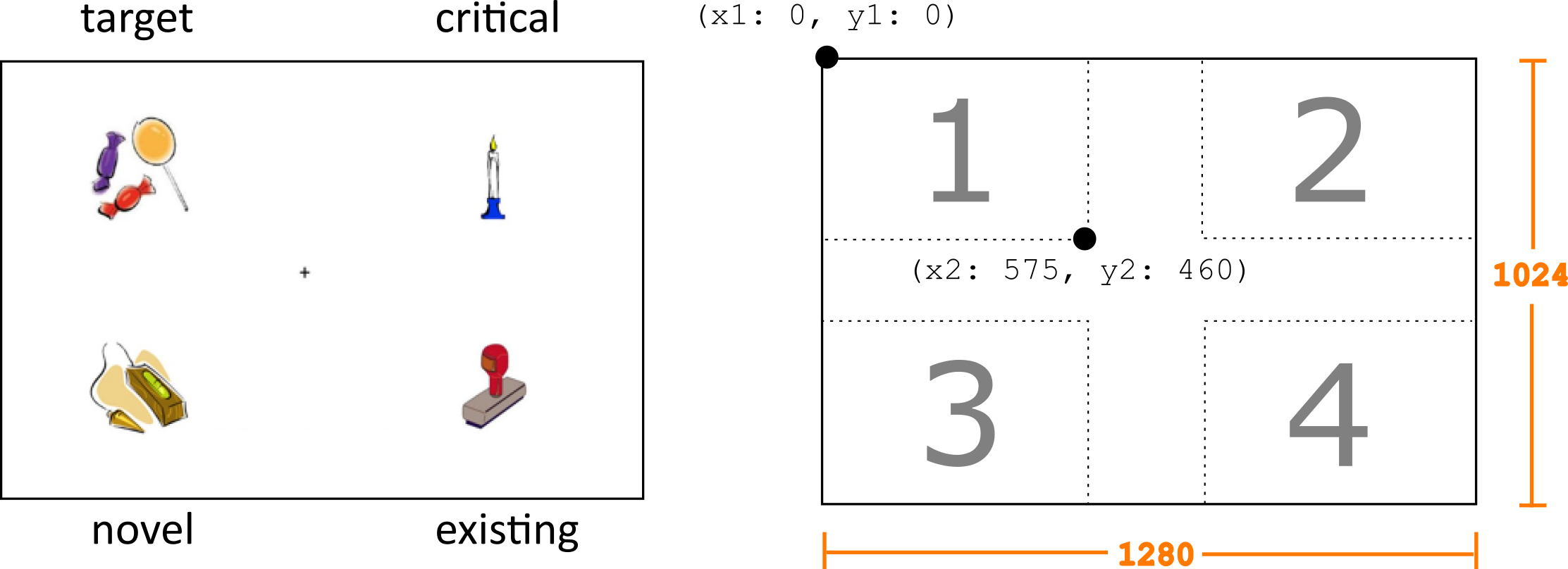
We know when people are looking relative to the disambiguation point for the trial (f_c), and we know where they are looking, because we have the (x, y) coordinates. But we yet don’t know which image they are looking at on each frame. So we have to map the two-dimensional gaze coordinates onto the coordinates of the images that was displayed on a given trial.
We know what pictures were shown on each trial from the data in the screens table (from data-raw/screens.csv).
arbitrary value uniquely identifying each display screen
loc
int
arbitrary integer identifying each rectangle
role
chr
image’s role in the set (target, critical, existing novel)
bitmap
chr
name of bitmap file
The loc variable is a number that refers to the four quadrants of the screen where the images appeared. We can get the pixel coordinates representing the top left and bottom right corners of each rectangle from the locations table.
horizontal coordinate of top-left corner in pixels
y1
int
vertical coordinate of top-left corner in pixels
x2
int
horizontal coordinate of bottom-right corner in pixels
y2
int
vertical coordinate of bottom-right corner in pixels
2.1 Image locations for each trial
2.1.1 Activity: Get coordinates
We want to combine the data from screens and locations with trial info to create the following table, which we will use later to figure out what image was being looked at (if any) on each frame of each trial. Save this information in a table named aoi (for Area Of Interest). You might need to reference Appendix A to see how to get sub_id and t_id into the table.
We can get sub_id and t_id from trials. But to get there from screens, we need to get the item version (iv_id) from stimuli. We can connect screens to stimuli through the screen id (s_id).
As a check, we should have four times the number of rows as trials (5644), because there should be four areas of interest for each trial. We can use stopifnot() to make our script terminate if this condition is not satisfied.
stopifnot( nrow(aoi) ==4*nrow(trials) )
2.2 Identifying frames where the gaze cursor is within an AOI
What we need to do now is look at the (x, y) coordinates in edat and see if they fall within the bounding box for each image in the aoi table for the corresponding trial.
2.2.1 Activity: Create frames_in
There are different ways to accomplish this task, but an effective strategy is just to join the eyedata (edat) to the aoi table and retain any frames where the x coordinate of the eye gaze is within the x1 and x2 coordinates of the rectangle, and the y coordinate is within the y1 and y2 coordinates. Because our AOIs do not overlap, the gaze can only be within a single AOI at a time.
frames_in <- edat %>%inner_join(aoi, c("sub_id", "t_id")) %>%filter(x >= x1, x <= x2, y >= y1, y <= y2) %>%select(sub_id, t_id, f_c, role)
2.2.2 Activity: Create frames_out
Create a table frames_out containing only those frames from edat where the gaze fell outside of any of the four image regions, and label those with the role (blank). Use the anti_join() function from dplyr to do so.
Combine frames_in and frames_out into a single table by concatenating the rows. Sort the rows so by sub_id, t_id, and f_c, and convert role into type factor with levels in this order: target, critical, existing, novel, and (blank). The resulting table should be called pog and have the format below.
We want to be able to use the data in pog to calculate probabilities of gazing at regions over time. However, we are not ready to do this yet.
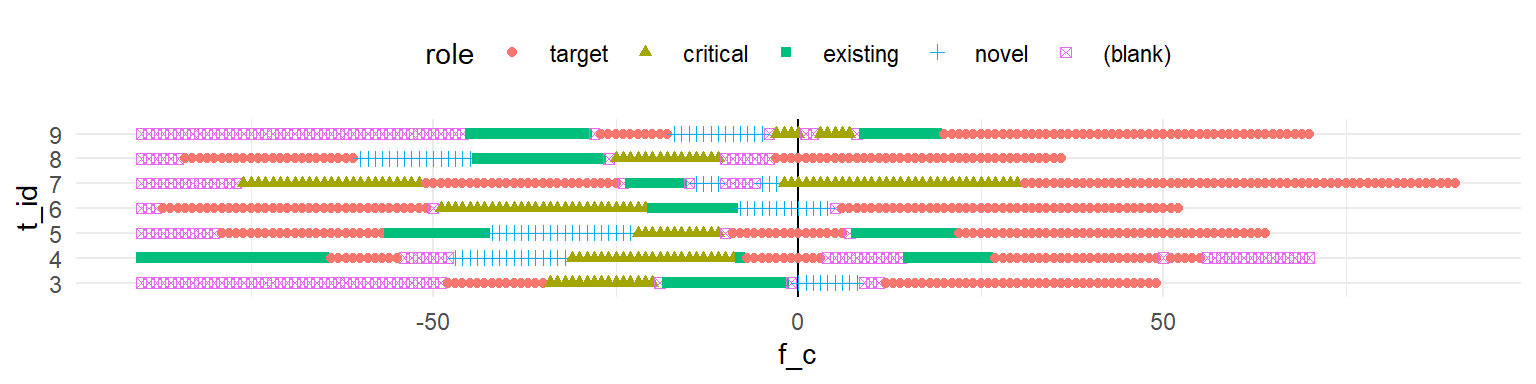
If we look at the first seven trials from subject 3, we can see that there is a problem, because the trials end at different times, due to variation in response time. If we plot the resulting data, we will have fewer and fewer data points as we progress through the trial.
A solution to this is to make each time series “cumulative to selection”, which means padding frames after the trial ends with artificial looks to the object that was selected. In other words, we pretend that the subject remained fixated on the selected object after clicking.
But before we do this, we should double check that trials also start at the same frame (-90). Once we pass this sanity check we can pad frames at the end.
start_frame <- edat %>%group_by(sub_id, t_id) %>%summarise(min_f_c =min(f_c), # get the minimum frame per trial.groups ="drop") %>%pull(min_f_c) %>%unique() # what are the unique values?## if the value is the same for every trial, there should be## just one element in this vectorstopifnot( length(start_frame) == 1L )start_frame
[1] -90
2.3.1 Activity: Selected object
Which object was selected on each trial? The trials table tells us which location was clicked (1, 2, 3, 4) but not which object. We need to figure out which object was clicked by retrieving that information from the screens table. The result should have the format below.
## which object was selected on each trial?selections <- trials %>%inner_join(stimuli, "iv_id") %>%inner_join(screens, c("s_id", "resploc"="loc")) %>%select(sub_id, t_id, role)
Now that we know what object was selected, we want to pad trials up to the latest frame in the dataset, which we determined during epoching as frame 90 (that is, 1.5 seconds after the disambiguation point).
We will use the crossing() function (from {tidyr}) to create a table with all combinations of the rows from selections with frames f_c from 0 to 90. Then, in the next activity, we will use anti_join() to pull out the combinations that are missing from pog, and use them in padding.
Use anti_join() to find out which frames in all_frames are missing from pog. Concatenate these frames onto pog, storing the result in pog_cts. The resulting table should have a variable pad which is FALSE if the frame is an original one, and TRUE if it was added through the padding procedure. Sort the rows of pog_cts by sub_id, t_id, and f_c. The format is shown below.