1 Building blocks of simulation
1.1 Coding preliminaries
If the main thing you do when using R is analyzing data, then it is likely that you haven't been exposed to many of the features of R and the tidyverse that are needed for data simulation, including random number generation (1.1.2), writing custom functions (1.1.6), iteration (1.1.3), nested tables (1.1.4.2), handling warnings and messages (1.2.2.1), and extracting statistics from model objects (1.2.3).
We will start by providing a basic overview on each of these topics through the task of generating an R script that performs a power simulation for a one-sample t-test for various effect and sample sizes. Although there are analytical solutions for computing power for this type of test, it is worth learning the general principles before dealing with the complexities of linear mixed-effects models.
In what follows, I will assume that you are familiar with how "pipes" work in R (either the base pipe, |> or the dplyr pipe, %>%) and the following one-table verbs from dplyr: select(), mutate(), and summarize().
1.1.1 Setting up the environment
When you're developing an R script, it is good practice to load in the packages you need at the top of the script.
suppressPackageStartupMessages({
library("dplyr") # select(), mutate(), summarize(), inner_join()
library("tibble") # tibble() [data entry]
library("purrr") # just for map()
library("tidyr") # nest(), unnest()
requireNamespace("broom") # don't load, just fail if it's not there
})We have wrapped these calls in suppressPackageStartupMessages() so that when don't get any of the messages that come up when packages are loaded each time we run the script. We are just using tidyverse functions anyway, so there shouldn't be any problems.
1.1.2 Random number generation
Simulating data means simulating random processes. Usually the random process we are trying to mimic is that of sampling, i.e., drawing a (presumably random) sample from a population.
This involves randomly generating numbers from some kind of statistical distribution. For many purposes we will use the univariate normal distribution via the function rnorm(), which is included in base R. If we want to simulate data from a multivariate normal distribution (which we will do in the next section), then we can use MASS::mvrnorm().
The key arguments to rnorm() are:
n |
the number of observations we want |
mean |
the population mean of the distribution (default 0) |
sd |
the population standard deviation (default 1) |
TASK: simulate 10 observations from a normal distribution with a mean of 0 and standard deviation of 5.
rnorm(10, sd = 5)
Functions like rnorm() will give you random output based on the state of the internal random number generator (RNG). If we want to get a deterministic output, we can "seed" the random number generator using set.seed(). (Often it makes sense to do this once, at the top of a script.) The function set.seed() takes a single argument, which is an arbitrary integer value that provides the 'starting point'.
TASK: set the seed to 1451 and then simulate 15 observations from a normal distribution with a mean of 600 and standard deviation of 80. If you do this right, your output should EXACTLY match the output below.
## [1] 383.2186 522.1162 503.1198 640.4056 628.0002 759.7153 595.5522 516.1018
## [9] 479.3662 587.9051 775.4601 684.2209 671.1479 597.2221 618.4092
1.1.3 Iterating using purrr::map()
To estimate power using simulation, we need to create our function and then run it many times—maybe 1,000 or 10,000 times to get a reliable estimate. Of course, we are not going to type a function call to do it that many times; it would be tedious, and besides, we might make mistakes. What we need is something to do the iteration for us, possible changing the input to our function each time.
In many programming languages, this is accomplished by writing a "for" loop. This is possible in R as well, but we're going to do this a different way that saves typing.
We are going to use the function purrr::map(). Let's look at an example. Suppose we had a vector of integers, x, and wanted to compute the logarithm (log()) of each one. If we didn't know about map(), we might type the following.
x <- c(1L, 4L, 7L, 9L, 14L) # the 'L' after each number means "long integer"
log(x[1])
log(x[2])
log(x[3])
log(x[4])
log(x[5])## [1] 0
## [1] 1.386294
## [1] 1.94591
## [1] 2.197225
## [1] 2.639057That's a lot of typing. With map(), we can just type this.
map(x, log)## [[1]]
## [1] 0
##
## [[2]]
## [1] 1.386294
##
## [[3]]
## [1] 1.94591
##
## [[4]]
## [1] 2.197225
##
## [[5]]
## [1] 2.639057Note that the output comes in the form of a list. If we wanted the output to be a vector of doubles, we could use map_dbl() instead.
map_dbl(x, log)## [1] 0.000000 1.386294 1.945910 2.197225 2.639057Now, by default, log() gives the natural logarithm (using base \(e\), Euler's number). What if we want to change the base? To do that we'd have to pass an additional argument base = 2 to log within map. We could add that like so
map_dbl(x, log, base = 2)## [1] 0.000000 2.000000 2.807355 3.169925 3.807355But this makes the syntax unclear: Is base = 2 an argument to map_dbl(), or to log()? Technically, it's an argument to map that is passed along to log(), but that is confusing. This makes things needlessly hard to debug. So the recommended way to do this is to call log() within map() as part of an anonymous function.
## [1] 0.000000 2.000000 2.807355 3.169925 3.807355This allows us to call log() in the "normal" way (i.e., the way we would do it if typing in the console. The \(.x) says to R "pass along the value from x you're currently working with to the function on the right hand side, giving this new value .x". Also, making explicit the passing of the value from map() to the function you wish to repeat makes it easy to work with situations where the varying value is not the first argument of that function.
If you have multiple arguments you need to pass to the function, you can do this using purrr::pmap(), whose first argument takes a list of function arguments.
For a deep dive into the topic of iteration, see R for Data Science by Wickham, Çentinkaya-Rundel, and Grolemund.
TASK: Write a call to map_dbl() that calculates the log of 3 but with bases varying from 2 to 7.
1.1.4 Creating "tibbles"
Much of what we'll be doing will involve working with datasets stored in tables, or tabular data (in R, a table is also called a data.frame). When you're analyzing data, you usually create these tables by importing data from a file (e.g., a CSV or Excel file with experiment data).
When you're simulating data, you need to create these tables yourself. The tibble package has functions that help make this easier. For current purposes, really the only function we need from this package is tibble::tibble(), which is an enhanced version of the base R data.frame() for manual data entry.
Let's assume we're creating information about the participants in a study. Each participant is given a unique id and we have recorded information about their age. We can enter this into a tibble() like so.
## # A tibble: 5 × 2
## id age
## <int> <int>
## 1 1 27
## 2 2 18
## 3 3 43
## 4 4 72
## 5 5 21
1.1.4.1 Save typing with rep(), seq(), and seq_len()
Let's now say you are going to run these participants on a Stroop interference task where they see color words printed in congruent or incongruent colors (e.g., the word "RED" printed in red font or green font) and have to name the color of the font. Let's assume that each person gets each word twice, once in the congruent condition and once in the incongruent condition. Now you want to make a table that has each of the six colors in each condition. The resulting table should look like this.
## # A tibble: 12 × 2
## word cond
## <chr> <chr>
## 1 red congruent
## 2 red incongruent
## 3 green congruent
## 4 green incongruent
## 5 blue congruent
## 6 blue incongruent
## 7 yellow congruent
## 8 yellow incongruent
## 9 purple congruent
## 10 purple incongruent
## 11 orange congruent
## 12 orange incongruentWe could type all that out manually but it would be tedious and prone to typos. Fortunately R has a function rep() that allows us to repeat values. Study the code below. until you understand how it works.
rep(1:4, each = 3)## [1] 1 1 1 2 2 2 3 3 3 4 4 4
rep(5:7, times = 4)## [1] 5 6 7 5 6 7 5 6 7 5 6 7## [1] 8 8 9 9 9TASK: Write code to recreate the Stroop stimuli table shown above using rep() to define the column values. Name the resulting table stimuli.
Two other functions that are useful in simulation are seq_len() and seq(). We'll e using these later. Examples are below.
## sequence of integers 1:length.out;
## if length.out == 0 then 'empty'
seq_len(length.out = 4)## [1] 1 2 3 4
seq(from = 2, to = 7, by = .5)## [1] 2.0 2.5 3.0 3.5 4.0 4.5 5.0 5.5 6.0 6.5 7.0
seq(from = 2, to = 7, length.out = 5)## [1] 2.00 3.25 4.50 5.75 7.001.1.4.2 Nested tibbles
Tibbles, like the data.frame class from which they are derived, are just specialized list structures. Lists are useful as data structures because unlike vectors, each element can be of a different data type (character, integer, double, factor). To be data frames, however, it is essential that each list element has the same length (number of elements).
A great feature of tibbles that differs from data.frame objects is that they can have columns whose values are themselves... tibbles. That is, we can have tibbles inside of tibbles, but we have to define those columns using the list() function.
## just basic tibbles
beatles <- tibble(name = c("John", "Paul", "Ringo", "George"),
instrument = c("guitar", "bass", "drums", "guitar"))
rolling_stones <- tibble(name = c("Keith", "Mick", "Charlie", "Bill"),
instrument = c("guitar", "vocals", "drums", "bass"))
## a tibble with tibbles as elements
boomer_bands <- tibble(band_name = c("Beatles", "Rolling Stones"),
band_members = list(beatles, rolling_stones))
boomer_bands## # A tibble: 2 × 2
## band_name band_members
## <chr> <list>
## 1 Beatles <tibble [4 × 2]>
## 2 Rolling Stones <tibble [4 × 2]>And if we then wanted to "expand" these nested tables we can do so using tidyr::unnest().
bb2 <- boomer_bands |>
unnest(band_members)
bb2## # A tibble: 8 × 3
## band_name name instrument
## <chr> <chr> <chr>
## 1 Beatles John guitar
## 2 Beatles Paul bass
## 3 Beatles Ringo drums
## 4 Beatles George guitar
## 5 Rolling Stones Keith guitar
## 6 Rolling Stones Mick vocals
## 7 Rolling Stones Charlie drums
## 8 Rolling Stones Bill bassAnd if we wanted to, we can then reverse the operation.
## # A tibble: 2 × 2
## band_name band_members
## <chr> <list>
## 1 Beatles <tibble [4 × 2]>
## 2 Rolling Stones <tibble [4 × 2]>Why is this useful? Well, mostly because it elegantly allows us to account for the multilevel structure of data, such as when you have trials nested within participants. But we'll see shortly how we can combine this with map() (which returns a list) to make columns whose elements are tibbles of simulated data, or analyses performed on those tibbles.
1.1.5 Combining tibbles
Often you'll end up with data scattered across different tables and need to merge it into a single table. The tidyverse provides powerful and efficient functions for merging data.
1.1.5.1 Cartesian join with dplyr::cross_join()
Occasionally what we want to do is combine all possible combinations of rows across two tables, in what is known as a "Cartesian join." For this, we can use the function dplyr::cross_join(). This is easiest to explain by an example.
some_letters <- tibble(letter = c("A", "B", "C"))
some_numbers <- tibble(numbers = seq_len(3))
cross_join(some_letters, some_numbers)## # A tibble: 9 × 2
## letter numbers
## <chr> <int>
## 1 A 1
## 2 A 2
## 3 A 3
## 4 B 1
## 5 B 2
## 6 B 3
## 7 C 1
## 8 C 2
## 9 C 3TASK: Above, we created the table participants and stimuli. Combine these two tables to create a table trials which creates all the possible trials in an experiment where each participant sees each stimulus once. The resulting table should have 60 rows. Before combining the tables, remove the column named age from participants.
## # A tibble: 60 × 3
## id word cond
## <int> <chr> <chr>
## 1 1 red congruent
## 2 1 red incongruent
## 3 1 green congruent
## 4 1 green incongruent
## 5 1 blue congruent
## 6 1 blue incongruent
## 7 1 yellow congruent
## 8 1 yellow incongruent
## 9 1 purple congruent
## 10 1 purple incongruent
## # ℹ 50 more rows
1.1.5.2 Inner join with dplyr::inner_join()
Sometimes what you need to do is combine information from two tables but you don't want all possible combinations; rather, you want to keep the rows from both tables that match on certain 'key' values.
For example, in the participants table we have each participant's age. If we wanted to combine that information with the information in trials (e.g., in order to analyze Stroop interference across age), then we'd need a way to get the age variable into trials. For this we can use an inner_join(), specifying the key column in the by argument to the function.
participants |>
inner_join(trials, by = join_by(id))## # A tibble: 60 × 4
## id age word cond
## <int> <int> <chr> <chr>
## 1 1 27 red congruent
## 2 1 27 red incongruent
## 3 1 27 green congruent
## 4 1 27 green incongruent
## 5 1 27 blue congruent
## 6 1 27 blue incongruent
## 7 1 27 yellow congruent
## 8 1 27 yellow incongruent
## 9 1 27 purple congruent
## 10 1 27 purple incongruent
## # ℹ 50 more rows1.1.6 Writing custom functions
In Monte Carlo simulation, you'll need to do the same thing (or variations on the same thing) over and over. Inevitably this means writing a 'function' that encapsulates some process. In the next section, where we learn about power simulation workflow, we'll write our own custom functions to simulate a data set (generate_data()), analyze the data (analyze_data()) and extract statistics (extract_stats()).
To create a function, you define an object using the function named function(). That sounds more confusing than it is, so let's jump right into an example. Suppose we want a function that adds two numbers together, x, and y, and returns the sum.
The code below will do the trick.
add_x_to_y <- function(x, y) {
x + y
}Now that we've defined the function, we can call it.
add_x_to_y(2, 3)## [1] 5Once we've defined it, it works like any other function in R. We can use it in map().
map(1:5, \(.x) add_x_to_y(.x, 10))## [[1]]
## [1] 11
##
## [[2]]
## [1] 12
##
## [[3]]
## [1] 13
##
## [[4]]
## [1] 14
##
## [[5]]
## [1] 15The part between the curly brackets defines the function body, which is where all of the computation happens. Data within the function is encapsulated—any variables that you define inside the function will be forgotten and wiped from memory after the function runs. By convention, results from the very last computation are returned to the calling process.
Sometimes it's useful to specify default arguments to save the user typing. So we might want to make the default value of y be 10.
add_x_to_y <- function(x, y = 10) {
x + y
}Now if we omit y it will set it to 10.
add_x_to_y(15)## [1] 251.2 Power simulation: Basic workflow
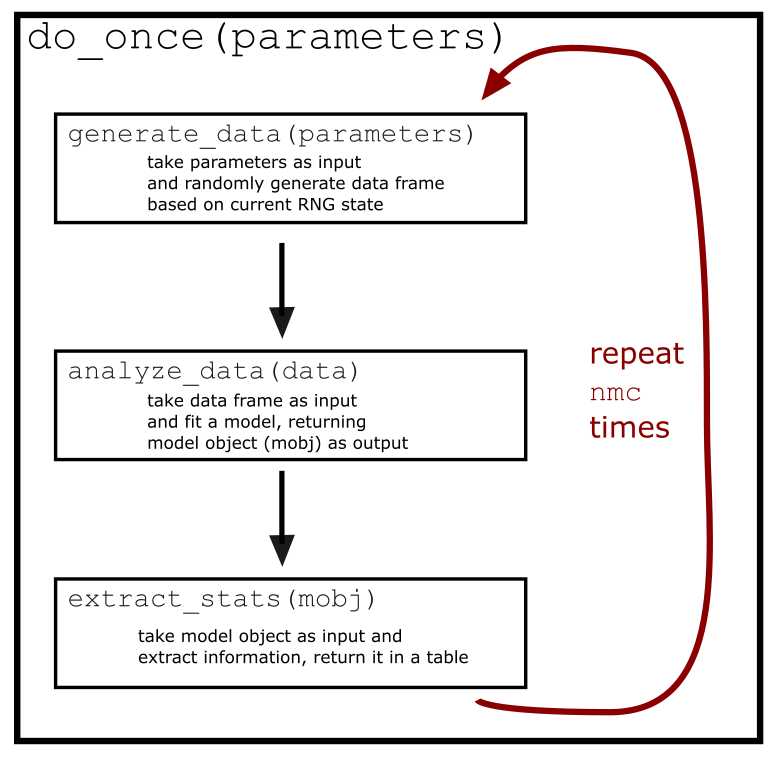
Figure 1.1: The basic workflow behind power simulation.
Now that we've gone over the programming basics, we are ready to start building a script to simulate power. To keep things simple, we'll simulate power for the simplest possible situation: a one-sample test, with a point null hypothesis of \(H_0: \mu = 0\).
Figure 1.1 presents the basic workflow.
1.2.1 Simulating a dataset
The first thing to do is to write (and test) a function generate_data() that takes population parameters and sample size info as input and creates simulated data as output using rnorm().
TASK: write a function generate_data() that takes three arguments as input: eff (the population intercept parameter), nsubj (number of subjects), and sd (the standard deviation, which should default to 1) and generates a table with simulated data using tibble(). The resulting table should have two columns, subj_id and dv (dependent variable; i.e., the result from rnorm()).
To test your function, run the code below and see if the output matches exactly.
set.seed(1451)
generate_data(5, 10, 2)## # A tibble: 10 × 2
## subj_id dv
## <int> <dbl>
## 1 1 -0.420
## 2 2 3.05
## 3 3 2.58
## 4 4 6.01
## 5 5 5.70
## 6 6 8.99
## 7 7 4.89
## 8 8 2.90
## 9 9 1.98
## 10 10 4.70generate_data <- function(????) {
## TODO: something with tibble()
}1.2.2 Analyzing the data
Unlike conventional statistical techniques (t-test, ANOVA), linear-mixed effects models are estimated iteratively and may not converge, or may yield estimates of covariance matrices that are "singular" (i.e., can be expressed in lower dimensionality). We will track statistics about singularity / nonconvergence in our simulations, but the repeated messages and warnings can be annoying when they are running, so we need to 'suppress' them. Now, for our simple one-sample power simulation we don't have to deal with these, but we are here to learn, so let's create a function that randomly throws warnings (20% of the time) and messages (20% of the time) so we can learn how to deal with them.
We will name this function annoy_user() and will embed it in our analysis function to simulation the messages we will get once we move to linear mixed-effects modeling.
annoy_user <- function() {
## randomly throw messages (20%) or warnings (20%) to annoy the user
## like a linear mixed-effects model
x <- sample(1:5, 1) # roll a five-sided die...
if (x == 1L) {
warning("Winter is coming.")
} else if (x == 2L) {
message("Approaching the singularity.")
} # otherwise do nothing
invisible(NULL) ## return NULL invisibly
}Now we're ready to write our analysis function. We'll include annoy_user() as part of this function.
TASK: use the starter code below to develop your analysis function for a one-sample test (hint: t.test()). The function should return the full 'data object' output from the t-test function.
analyze_data <- function(dat) {
annoy_user()
## TODO add in your analysis here
}
set.seed(1451)
generate_data(0, 10) |>
analyze_data()##
## One Sample t-test
##
## data: pull(dat, dv)
## t = -0.78487, df = 9, p-value = 0.4527
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## -1.1935688 0.5786762
## sample estimates:
## mean of x
## -0.3074463Note that dat |> pull(dv) is the tidyverse way of extracting a column from a data frame.
1.2.2.1 Handling warnings and messages
OK, if we run generate_data() |> analyze_data() a bunch of times, it's going to occasionally give us bothersome warnings and messages.
result <- map(1:20, \(.x) generate_data(0, 10) |> analyze_data())## Warning in annoy_user(): Winter is coming.## Approaching the singularity.## Warning in annoy_user(): Winter is coming.
## Warning in annoy_user(): Winter is coming.
## Warning in annoy_user(): Winter is coming.
## Warning in annoy_user(): Winter is coming.## Approaching the singularity.We have two options here: we can trap them if we want to react in some way when they occur; or, we can suppress them so that they don't clutter up the output when the model is running. Since there are ways to check convergence / singularity after the fact, we'll opt for suppression. Fortunately R has the functions suppressMessages() and suppressWarnings(), and all we have to do is wrap them around the part of the code that is generating the side effects. So, our final analysis function will be as follows.
analyze_data <- function(dat) {
suppressWarnings(
suppressMessages({
annoy_user()
}))
dat |>
pull(dv) |>
t.test()
}Let's try it again.
result <- map(1:20, \(.x) generate_data(0, 10) |> analyze_data())For future reference, in cases where you would want to trap an error/message/warning, you would use the tryCatch() function instead. See https://adv-r.hadley.nz/conditions.html if you want a deep dive into the topic of condition handling.
1.2.3 Extracting statistics
The output of t.test() gives us a data object, but it would be better if we could extract all the relevant stats in the form of a table. We want a function that takes a statistical data object (or fitted model object, mobj) and return a table with statistical information. This is where broom::tidy() comes to the rescue.
Unfortunately this function won't work for linear mixed-effects models, so we'll have to extract what we need in other ways when we get there. But we'll just use broom::tidy() for now.
extract_stats <- function(mobj) {
mobj |>
broom::tidy()
}We call tidy() using broom::tidy() because we didn't load the package. Generally if you just need a single package function it's a good idea not to load it, to avoid possible namespace clashes.
1.2.4 Wrapping it all in a single function
Now we've completed the three functions shown in Figure 1.1, and can string them together.
generate_data(0, 10) |>
analyze_data() |>
extract_stats()## # A tibble: 1 × 8
## estimate statistic p.value parameter conf.low conf.high method alternative
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
## 1 -0.360 -1.24 0.246 9 -1.01 0.295 One Sampl… two.sidedWe want to do this many times. The way we'll approach this is to create a tibble where each row has the generated data, the model object, and the statistics from a single run.
Here's code to create a tibble with run_id (to identify each row) and a list-column dat, each element of which contains simulated data.
nmc <- 20L # number of Monte Carlo runs
result <- tibble(run_id = seq_len(nmc),
dat = map(run_id, \(.x) generate_data(0, 10)))TASK: Update the code above to add two additional rows, mobj (a list-column) which has the result of applying analyze_data() to each generated dataset, and stats (a list-column) which has the result of applying extract_stats() to each element mobj.
The table result should look as follows.
## # A tibble: 20 × 4
## run_id dat mobj stats
## <int> <list> <list> <list>
## 1 1 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 2 2 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 3 3 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 4 4 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 5 5 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 6 6 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 7 7 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 8 8 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 9 9 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 10 10 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 11 11 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 12 12 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 13 13 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 14 14 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 15 15 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 16 16 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 17 17 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 18 18 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 19 19 <tibble [10 × 2]> <htest> <tibble [1 × 8]>
## 20 20 <tibble [10 × 2]> <htest> <tibble [1 × 8]>1.2.4.1 Calculating power
We're getting so close! Now what we need to do is compute power based on the statistics we have calculated (in the stats) column. We can extract these using select() and unnest() like so.
## # A tibble: 20 × 9
## run_id estimate statistic p.value parameter conf.low conf.high method
## <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 1 -0.338 -1.20 0.260 9 -0.974 0.298 One Sample t…
## 2 2 0.482 1.74 0.115 9 -0.144 1.11 One Sample t…
## 3 3 -0.258 -1.16 0.274 9 -0.761 0.244 One Sample t…
## 4 4 -0.113 -0.491 0.635 9 -0.632 0.407 One Sample t…
## 5 5 -0.447 -1.61 0.143 9 -1.08 0.183 One Sample t…
## 6 6 0.0683 0.209 0.839 9 -0.669 0.806 One Sample t…
## 7 7 0.264 0.810 0.439 9 -0.473 1.00 One Sample t…
## 8 8 -0.622 -1.86 0.0959 9 -1.38 0.135 One Sample t…
## 9 9 -0.0249 -0.106 0.918 9 -0.555 0.505 One Sample t…
## 10 10 -0.139 -0.536 0.605 9 -0.728 0.449 One Sample t…
## 11 11 -0.597 -2.97 0.0157 9 -1.05 -0.143 One Sample t…
## 12 12 0.172 0.533 0.607 9 -0.556 0.899 One Sample t…
## 13 13 0.449 1.28 0.232 9 -0.343 1.24 One Sample t…
## 14 14 -0.218 -1.04 0.324 9 -0.691 0.254 One Sample t…
## 15 15 -0.478 -1.43 0.187 9 -1.23 0.279 One Sample t…
## 16 16 -0.305 -0.808 0.440 9 -1.16 0.549 One Sample t…
## 17 17 -0.627 -1.54 0.158 9 -1.55 0.295 One Sample t…
## 18 18 0.111 0.390 0.706 9 -0.532 0.753 One Sample t…
## 19 19 -0.762 -5.60 0.000335 9 -1.07 -0.454 One Sample t…
## 20 20 -0.122 -0.480 0.642 9 -0.697 0.453 One Sample t…
## # ℹ 1 more variable: alternative <chr>Now adapt the above code into a function compute_power() that takes a table x (e.g., result) as input along with the alpha level (defaulting to .05) and returns power as a table with nsig (number of significant runs), N (total runs), power (proportion of runs that were significant).
You got p.value as a column after unnesting.
p.value < alpha will compare each p value to alpha and return TRUE if it is statistically significant, false otherwise.
Do something with summarize() to calculate the number of runs that were significant.
TASK: Let's wrap the above code in a function do_once(), that we can run in batch mode as well as interactively, and that goes all the way from from generate_data() to compute_power(). This function should accept as input arguments nmc (number of Monte Carlo runs), eff (effect size), nsubj (number of subjects), sd (standard deviation), and alpha level alpha (defaulting to .05). The function should return the results of compute_power().
Once complete, test it using the code below. Your output should be identical.
set.seed(1451)
do_once(nmc = 1000, eff = 0, nsubj = 20, sd = 1, alpha = .05)## # A tibble: 1 × 3
## nsig N power
## <int> <int> <dbl>
## 1 47 1000 0.047OK, one last amendment to do_once(). This function can take a long time to return depending on the number of Monte Carlo runs it needs to complete. So it's useful to send a message to the user so the user knows that the program didn't just hang. Let's do that.
do_once <- function(nmc, eff, nsubj, sd, alpha = .05) {
message("computing power over ", nmc, " runs with eff=",
eff, "; nsubj=", nsubj, "; sd = ", sd, "; alpha = ", alpha)
tibble(run_id = seq_len(nmc),
dat = map(run_id, \(.x) generate_data(eff, nsubj, sd)),
mobj = map(dat, \(.x) analyze_data(.x)),
stats = map(mobj, \(.x) extract_stats(.x))) |>
compute_power(alpha)
}OK, now that you've got this far, you should take a step back and celebrate that you have a function, do_once(), that runs a power simulation given the population parameters, alpha level, and sample size as user input.
1.2.5 Calculating power curves
So, we've now calculated a power curve for a single parameter setting. But we usually want to calculate a power curve so that we can see how power varies as a function of some parameter (usually, effect size and sample size). How can we do that?
Well, given that we've encapulated the guts of our simulation in a single function, it is a simple matter of just calling that function repeatedly with different inputs and storing the results. Sound familiar?
TASK: Create a tibble with parameter values for eff (effect size) going in 5 steps from 0 to 1. The tibble should have a column pow, which has the results from do_once() called for that value of eff (and with nsubj, sd, and nmc held constant at 20, 1, and 1000 respectively).
If you set the seed to 1451 before you run it, then print it out, the resulting table should look like this.
## # A tibble: 5 × 4
## eff nsig N power
## <dbl> <int> <int> <dbl>
## 1 0 47 1000 0.047
## 2 0.25 203 1000 0.203
## 3 0.5 576 1000 0.576
## 4 0.75 900 1000 0.9
## 5 1 987 1000 0.987
seq(0, 1, length.out = 5)pow_result <- tibble(eff = seq(???),
pow = map(eff, ???)) |>
unnest(pow)
pow_result1.3 The full script
Running power simulations can take a long time. We surely want to save the results when we're done, and probably make it reproducible by setting the seed before calling any functions. But that's it! We now have a self-contained, reproducible script for calculating power.
#############################
## ADD-ON PACKAGES
suppressPackageStartupMessages({
library("dplyr") # select(), mutate(), summarize(), inner_join()
library("tibble") # tibble() [data entry]
library("purrr") # just for map()
library("tidyr") # nest(), unnest()
requireNamespace("broom") # don't load, just fail if it's not there
})
#############################
## MAIN FUNCTIONS
generate_data <- function(eff, nsubj, sd = 1) {
tibble(subj_id = seq_len(nsubj),
dv = rnorm(nsubj, mean = eff, sd = sd))
}
analyze_data <- function(dat) {
suppressWarnings(
suppressMessages({
annoy_user()
}))
dat |>
pull(dv) |>
t.test()
}
extract_stats <- function(mobj) {
mobj |>
broom::tidy()
}
#############################
## UTILITY FUNCTIONS
annoy_user <- function() {
## randomly throw messages (20%) or warnings (20%) to annoy the user
## like a linear mixed-effects model
x <- sample(1:5, 1) # roll a five-sided die...
if (x == 1L) {
warning("Winter is coming.")
} else if (x == 2L) {
message("Approaching the singularity.")
} # otherwise do nothing
invisible(NULL) ## return NULL invisibly
}
compute_power <- function(x, alpha = .05) {
x |>
select(stats) |>
unnest(stats) |>
summarize(nsig = sum(p.value < alpha),
N = n(),
power = nsig / N)
}
do_once <- function(nmc, eff, nsubj, sd, alpha = .05) {
message("computing power over ", nmc, " runs with eff=",
eff, "; nsubj=", nsubj, "; sd = ", sd, "; alpha = ", alpha)
tibble(run_id = seq_len(nmc),
dat = map(run_id, \(.x) generate_data(eff, nsubj, sd)),
mobj = map(dat, \(.x) analyze_data(.x)),
stats = map(mobj, \(.x) extract_stats(.x))) |>
compute_power(alpha)
}
#############################
## MAIN PROCEDURE
## TODO: possibly set the seed to something for reproducibility?
pow_result <- tibble(eff = seq(0, 1, length.out = 5),
pow = map(eff, \(.x) do_once(1000, .x, 20, 1))) |>
unnest(pow)
pow_result
outfile <- "simulation-results-one-sample.rds"
saveRDS(pow_result, file = outfile)
message("saved results to '", outfile, "'")