Semester One: How do I translate a study design into a statistical model for analysis?
Semester Two: How do I develop an idea and translate it into a study design?
The approach
We want our analyses to be:
reproducible
transparent
generalizable
flexible
Recipes encourage poor practice
“If all you have is a hammer, everything looks like a nail”
violation of assumptions
especially: independence
discretization of predictors
treating categorical data as continuous
over-aggregation
mindless statistics
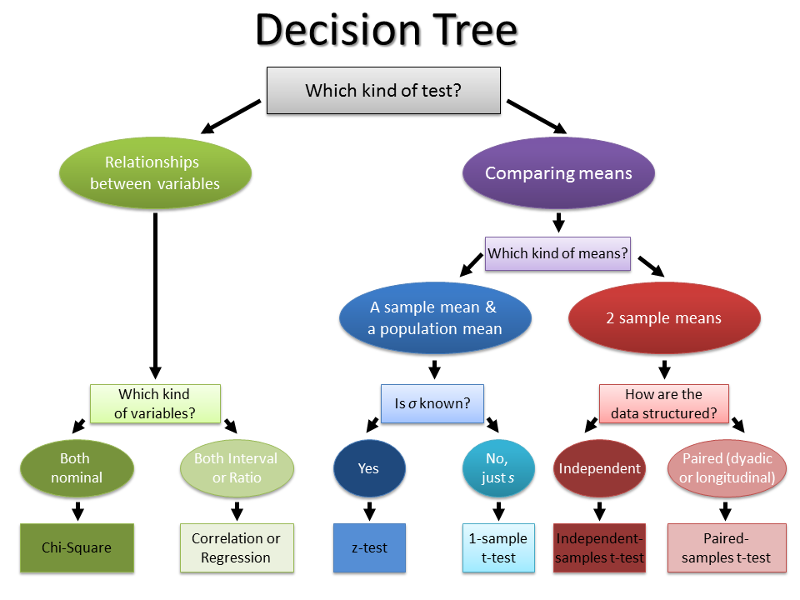
What do they have in common?
t-test
correlation & regression
multiple regression
analysis of variance
mixed-effects modeling
All are special cases of the General Linear Model (GLM).
GLM approach
Define a mathematical model representing the processes that are assumed to give rise to the data
Estimate the parameters of the model
Validate the model
Transparently report what you did
share your code
anonymize and share your data (ethics permitting)
Models are just… models
A statistical model is a simplification and idealization of reality that captures our key assumptions about the processes underlying data (the data generating process or DGP).
Importance of data simulation
Data simulation is a litmus test of understanding a statistical approach.
Can you generate simulated data that would meet the assumptions of the approach?
If not, you don’t understand it (yet!)
Being able to specify the DGP is key to study planning (power)
Example: Parent reflexes
Does being the parent of a toddler sharpen your reflexes?
simple response time to a flashing light
dependent (response) variable: mean RT for each parent
Two Sample t-test
data: parents and control
t = -0.5871, df = 98, p-value = 0.5585
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-20.89804 11.35576
sample estimates:
mean of x mean of y
480.6351 485.4062
Analysis of variance (ANOVA)
dat <-tibble(group =rep(c("parent", "control"), c(length(parents), length(control))),rt =c(parents, control))dat